src
src.Rmd
# most chunks in this vignette are not evaluated because I'm not sure how to
# save nested dictionaries yet, and calling the api borks in knitting but
# not in console.
# load R analysis package
library(supermetroid)
# other tools
library(tidyverse)
# so R can talk to Python
library(reticulate)
# for html tables
library(gt)speedrun.com
Speedrun.com is (according to the the two speed runners I’ve spoken to) the canonical leaderboard for speed runners on the internet. Because it is believed to be the most complete set (I’d like to check this with data) of speed runs, the canonical ranking of players amongst the community is their Speedrun.com ranking.
data(src_df)
all_run_raincloud(src_run_df)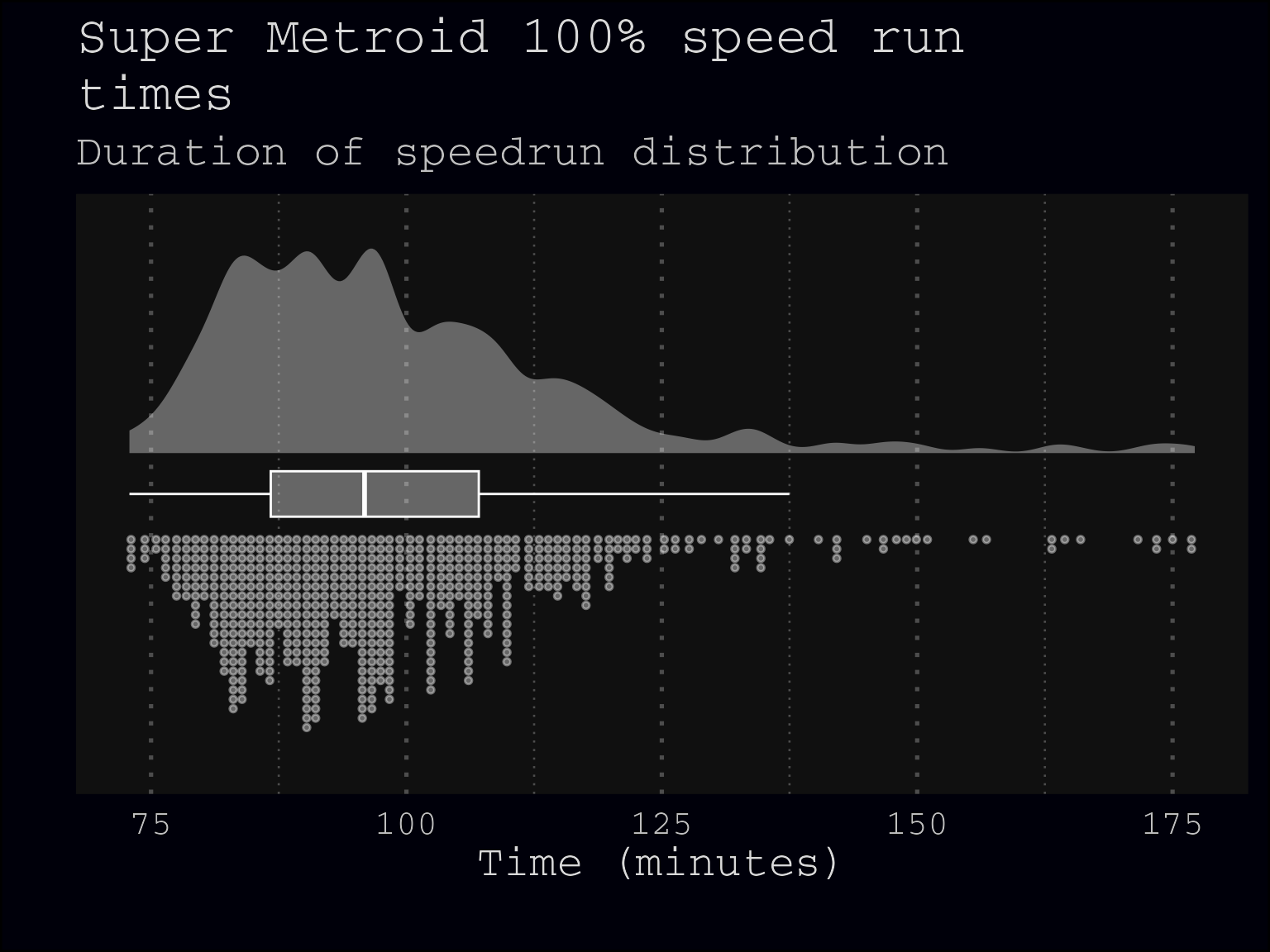
The code below is how these data were extracted and cleaned for the visualisation above.
| rank | player_name | date | t_human | country | run_id | t_s | src_user_guest | uri_player | api_call |
|---|---|---|---|---|---|---|---|---|---|
| 1 | ShinyZeni | 2023-06-20 | PT1H12M47S | United States | ywrjqd9m | 4367.000 | user | https://www.speedrun.com/api/v1/users/zxzno3ex | zxzno3ex |
| 2 | zoast | 2021-02-24 | PT1H12M55S | Palau | yo75d4dm | 4375.000 | user | https://www.speedrun.com/api/v1/users/18v6k4nx | 18v6k4nx |
| 3 | Behemoth87 | 2021-12-08 | PT1H12M55.930S | England | m36d0q6m | 4375.930 | user | https://www.speedrun.com/api/v1/users/zxz2wy4x | zxz2wy4x |
| 4 | Gebbu | 2023-05-08 | PT1H13M12S | Norway | m3qo724y | 4392.000 | user | https://www.speedrun.com/api/v1/users/xk49m26j | xk49m26j |
| 5 | Static_Shock | 2023-06-10 | PT1H13M58.367S | Brazil | m3qrx76y | 4438.367 | user | https://www.speedrun.com/api/v1/users/x35ve3kj | x35ve3kj |
| 6 | CScottyW | 2023-06-27 | PT1H14M18S | United States | zpw9px8y | 4458.000 | user | https://www.speedrun.com/api/v1/users/18q3n0dj | 18q3n0dj |
api
There is a Python module for accessing speedrun.com .
# load Python modules
import srcomapi, srcomapi.datatypes as dt
import pandas as pd # for wrangling into df
import time
import json
import math
# Tak, Anthony :)
import pprint
pp = pprint.PrettyPrinter(indent=4)Get data
# this chunk is only evaluated when data is updated
# this chunk code copied from
# https://github.com/blha303/srcomapi
# call api
src_api = srcomapi.SpeedrunCom(); src_api.debug = 1
# It's recommended to cache the game ID and use it for future requests.
# Data is cached for the current session by classname/id so future
# requests for the same game are instantaneous.
src_api.search(srcomapi.datatypes.Game, {"name": "super metroid"})
# can we add a historical == true to this?
game = _[0]
srcomapi_runs = {}
for category in game.categories:
if not category.name in srcomapi_runs:
srcomapi_runs[category.name] = {}
if category.type == 'per-level':
for level in game.levels:
srcomapi_runs[category.name][level.name] = dt.Leaderboard(src_api, data=src_api.get("leaderboards/{}/level/{}/{}?embed=variables".format(game.id, level.id, category.id)))
else:
srcomapi_runs[category.name] = dt.Leaderboard(src_api, data=src_api.get("leaderboards/{}/category/{}?embed=variables".format(game.id, category.id)))
### 100% Super Metroid leaderboard
src_leaderboard = srcomapi_runs['100%']
# list of dictionaries
type(src_leaderboard)
# Only nested object seems to be runs
src_leaderboard.keys()
# Don't know what this is, is it useful?
# generator object DataType
src_leaderboard.variables
type(src_leaderboard.runs)
type(src_leaderboard.runs[0])
src_leaderboard.runs[0]['run'].data
# convert the run objects to dictionaries
src_runs = [src_leaderboard.runs[x]['run'].data for x in range(len(src_leaderboard.runs))]Get runs
# list of
type(src_runs)
# dictionaries
#> Error: NameError: name 'src_runs' is not defined
type(src_runs[1])
# extracting specific values
#> Error: NameError: name 'src_runs' is not defined
src_runs[0].keys()
# rank
#> Error: NameError: name 'src_runs' is not defined
src_leaderboard.runs[0]['place']
# run as a nested dictionary
#> Error: NameError: name 'src_leaderboard' is not defined
src_runs[0].keys()
# Inspect bits we want to extract
#> Error: NameError: name 'src_runs' is not defined
src_runs[5]['id']
#> Error: NameError: name 'src_runs' is not defined
src_runs[5]['times']
#> Error: NameError: name 'src_runs' is not defined
src_runs[5]['date']
#> Error: NameError: name 'src_runs' is not defined
for x in range(len(src_runs)):
print(src_runs[x]['players'][0])
#> Error: NameError: name 'src_runs' is not definedRun dataframe
| src_run_df | description | from |
|---|---|---|
| date | timestamp of run upload | runs[index]['run']['date'] |
| run_id | unique identifier of run | runs[index]['run']['date'] |
| run_time | total time of run in s or ms | runs[index]['run']['times']['realtime_t'] |
| player_id | unique identifier of player | player id == run id, debug extraction |
| rank | rank, empty if historical, currently don’t have historical obs | src_runs[x]['place'] |
n_obs = len(src_runs)
# how to get splits? [src_runs][x]['run']['splits']
# get a list of players
#> Error: NameError: name 'src_runs' is not defined
src_players = [pd.DataFrame(
src_runs[x]['players']) for x in range(len(src_runs))]
# check length of run-player is same
#> Error: NameError: name 'src_runs' is not defined
len(src_players)
# i think these are all single-depth dicts, and can be flattened
#> Error: NameError: name 'src_players' is not defined
pp.pprint(src_players[0:3])
# concatenate players into df
#> Error: NameError: name 'src_players' is not defined
src_player_df = pd.concat(src_players).rename(columns={
'uri':'uri_player',
'id':'src_id',
'rel':'src_user_guest'
})
# create api call
#> Error: NameError: name 'src_players' is not defined
src_player_df["api_call"] = src_player_df[
'src_id'].fillna(src_player_df['name'])
# ugh couldn't figure out how to lambda that ifelse
#> Error: NameError: name 'src_player_df' is not defined
src_player_df = src_player_df.drop(columns = ['src_id', 'name'])
# take a look
#> Error: NameError: name 'src_player_df' is not defined
src_player_df.head()
# check number of records should match runs
#> Error: NameError: name 'src_player_df' is not defined
src_player_df.shape[0]
# extract elements with list comprehension (new tool for me)
#> Error: NameError: name 'src_player_df' is not defined
src_run_df = pd.DataFrame({
# need to inspect what happens to historical ranking
'rank' : [src_leaderboard.runs[x]['place'] for x in range(n_obs)],
't_human' : [src_runs[x]['times']['primary']
for x in range(n_obs)],
'date' : [src_runs[x]['date'] for x in range(n_obs)],
't_s' : [src_runs[x]['times']['realtime_t']
for x in range(n_obs)],
'run_id' : [src_runs[x]['id'] for x in range(n_obs)]
})
# check that run-players and runs have same length
#> Error: NameError: name 'n_obs' is not defined
src_player_df.shape[0] == src_run_df.shape[0]
#> Error: NameError: name 'src_player_df' is not defined
src_run_runners_df = pd.concat([src_run_df.reset_index(drop = True), src_player_df.reset_index(drop = True)], axis=1)
# check we still have the same number of runs
# should be one row per run
#> Error: NameError: name 'src_run_df' is not defined
len(src_leaderboard.runs) == src_run_runners_df.shape[0]
# inspect runs dataframe
#> Error: NameError: name 'src_leaderboard' is not defined
src_run_runners_df.head()
#> Error: NameError: name 'src_run_runners_df' is not defined
src_run_runners_df.shape
#> Error: NameError: name 'src_run_runners_df' is not defined
src_run_runners_df.columns
#> Error: NameError: name 'src_run_runners_df' is not definedPlayer data
| layer_df | description |
|---|---|
| player_id | unique identifier of player |
| player_handle | human-readable unique tag |
| location | geographic location of player |
# this loop fails because not all ids are valid
# get a list of player records for each valid player id
src_location = []
src_name = []
player = src_run_runners_df.api_call[7]
# well this turned into something horrible, despite my best efforts
# but I think it works
#> Error: NameError: name 'src_run_runners_df' is not defined
for player in list(src_run_runners_df.api_call):
print("loop index")
print(len(src_location))
print(len(src_name))
print(player)
try:
user = src_api.get_user(player)
src_name.append(user.name)
try:
src_location.append(user.location['country']['names']['international'])
except:
src_location.append("no record")
except:
try:
src_api.search(srcomapi.datatypes.Player, {'name': player})
api_player = _[0]
src_location.append(api_player.location)
src_name.append(player)
except:
src_location.append("no record")
src_name.append(player)
time.sleep(0.5)
#> Error: NameError: name 'src_run_runners_df' is not defined
src_run_runners_df.shape[0]
#> Error: NameError: name 'src_run_runners_df' is not defined
len(src_location)
#> 0
len(src_name)
#> 0
print(src_location[0:9])
#> []
print(src_name[0:9])
# do we have the correct number of players? (repeats expected, 1/run)
#> []src_raw_df = src_run_runners_df.assign(
player_name = src_name,
country = src_location
)
#> Error: NameError: name 'src_run_runners_df' is not defined
src_raw_df.shape
#> Error: NameError: name 'src_raw_df' is not defined
src_raw_df.tail()
#> Error: NameError: name 'src_raw_df' is not defined
src_raw_df.head()
#> Error: NameError: name 'src_raw_df' is not defined
# bring it over into sweet, sweet easier R
src_all_obs_df <- py$src_raw_df
#> Error in eval(expr, envir, enclos): AttributeError: module '__main__' has no attribute 'src_raw_df'
src_df <-
src_all_obs_df %>%
select(rank,
player_name,
date,
t_human,
country,
contains("id"),
everything())
#> Error in eval(expr, envir, enclos): object 'src_all_obs_df' not found
src_df %>% head()
#> rank player_name date t_human country run_id t_s
#> 1 1 ShinyZeni 2023-06-20 PT1H12M47S United States ywrjqd9m 4367.000
#> 2 2 zoast 2021-02-24 PT1H12M55S Palau yo75d4dm 4375.000
#> 3 3 Behemoth87 2021-12-08 PT1H12M55.930S England m36d0q6m 4375.930
#> 4 4 Gebbu 2023-05-08 PT1H13M12S Norway m3qo724y 4392.000
#> 5 5 Static_Shock 2023-06-10 PT1H13M58.367S Brazil m3qrx76y 4438.367
#> 6 6 CScottyW 2023-06-27 PT1H14M18S United States zpw9px8y 4458.000
#> src_user_guest uri_player api_call
#> 1 user https://www.speedrun.com/api/v1/users/zxzno3ex zxzno3ex
#> 2 user https://www.speedrun.com/api/v1/users/18v6k4nx 18v6k4nx
#> 3 user https://www.speedrun.com/api/v1/users/zxz2wy4x zxz2wy4x
#> 4 user https://www.speedrun.com/api/v1/users/xk49m26j xk49m26j
#> 5 user https://www.speedrun.com/api/v1/users/x35ve3kj x35ve3kj
#> 6 user https://www.speedrun.com/api/v1/users/18q3n0dj 18q3n0dj
usethis::use_data(src_df, overwrite=TRUE)Visualise runs
Now we have the data from speedrun.com leaderboard, we can plot the distribution of runs.
# get the data from python into R
all_run_raincloud(src_df_all_obs)
#> Error in eval(expr, envir, enclos): object 'src_df_all_obs' not foundWe have a handful of 0 entries and some > 3 hours.
# how many runs are really low?
src_df_all_obs %>%
filter(t_s < 4000 | t_s > 3 * 60 * 60)
#> Error in eval(expr, envir, enclos): object 'src_df_all_obs' not foundThe 0 entries are run times where gametime was captured,
but realtime was not by the tool the player used to record
the run. Our analyses are on realtime, so we will exclude
these observations.
We are also interest in comparing speed runners, as opposed to those logging playing through the game, which takes some hours.
(prop_greater_3hrs <- sum(src_df_all_obs$t_s > 3 * 60 * 60) /
nrow(src_df_all_obs))
#> Error in eval(expr, envir, enclos): object 'src_df_all_obs' not foundSince only {r round(prop_greater_3hrs, 2) * 100}% of runs are greater than 3 hours, these are negligible, and arguably not speed runs. We will define a Super Metroid speed run, for this analysis, to be a Super Metroid 100% run that takes under 3 hours.
Raincloud
src_df_all_obs %>%
filter(
# remove 0 length runs
t_s > 0,
# exclude runs > 3 hours
t_s < 3 * 60 * 60) %>%
all_run_raincloud()
#> Error in eval(expr, envir, enclos): object 'src_df_all_obs' not foundWrite run data from speedrun.com to supermetroid
# this chunk is evaluated when data is updated
src_df <-
src_df_all_obs %>%
# filter runs to less than 3 hours, and weird 0 length records
# we won't consider these speed runs
filter(t_s > 0, t_s < 3 * 60 * 60) %>%
mutate(
rank = as.integer(rank),
player_name = as.character(player_name),
date = ymd(date),
country = as.character(location)
)
head(src_df)