GEUS Application
Charles T. Gray
simeta

Math is in the manuscript, Statistics and Data Science, 2019
library(simeta)
# simulate dataset of 3 studies
example_meta <- sim_stats(
measure = "mean",
measure_spread = "sd",
n_df = sim_n(),
wide = TRUE, # metafor interoperability
rdist = "lnorm", # sampling distribution
par = list(shape = 0.25, scale = 1),
tau_sq = 0.4, # between-study error
effect_ratio = 1.2 # true effect
)
# output in html using quarto
example_meta %>% gt()| study | effect_c | effect_spread_c | n_c | effect_i | effect_spread_i | n_i |
|---|---|---|---|---|---|---|
| Elphir_1984 | 2.549209 | 2.727634 | 54 | 2.131478 | 1.944986 | 57 |
| Imrazôr_1992 | 2.605021 | 3.322262 | 86 | 3.071742 | 4.267402 | 88 |
| Yavanna_2015 | 1.749192 | 1.718549 | 30 | 3.973773 | 4.935866 | 27 |
What is a meta-analysis?
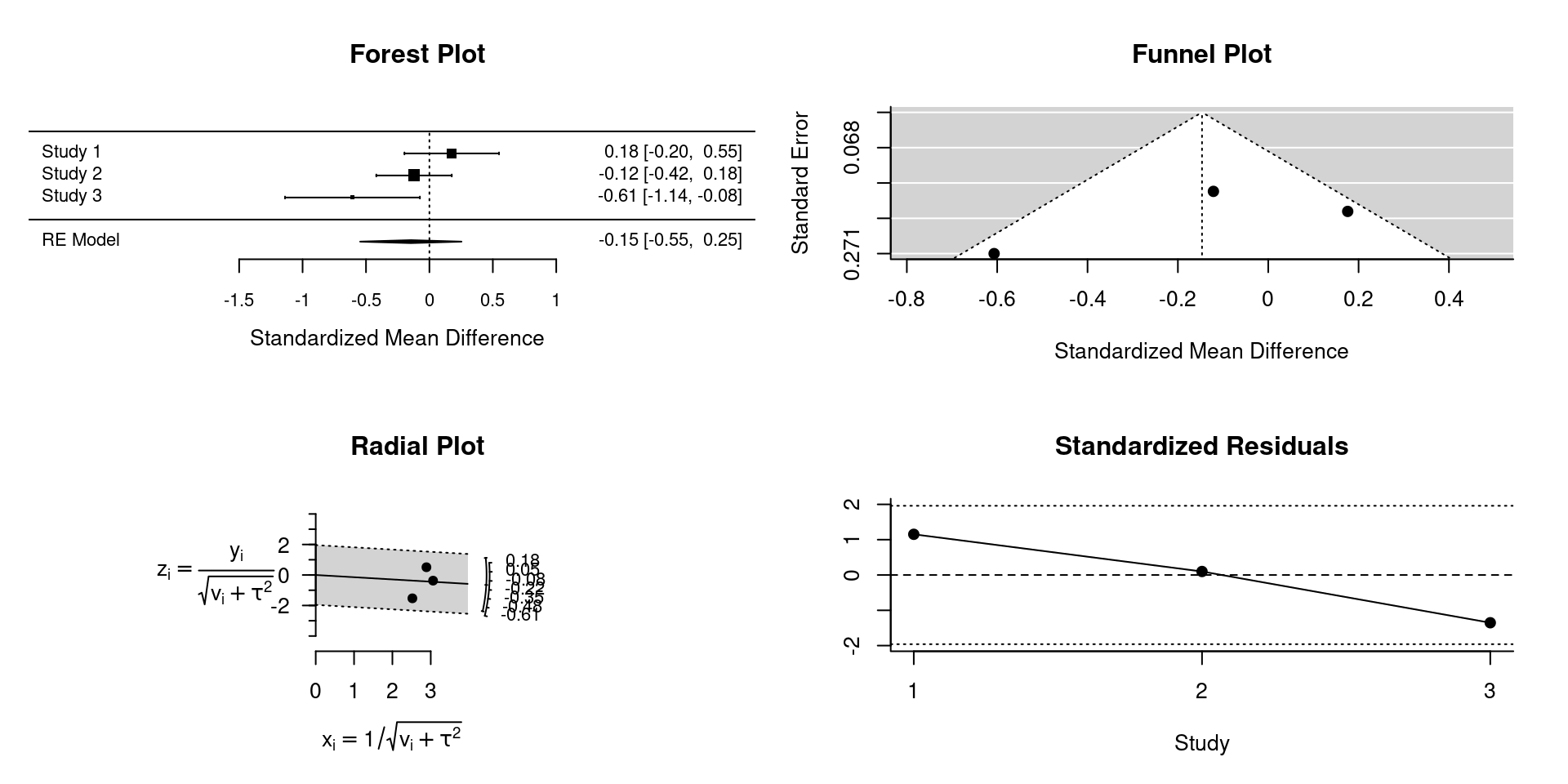
How was simeta implemented?
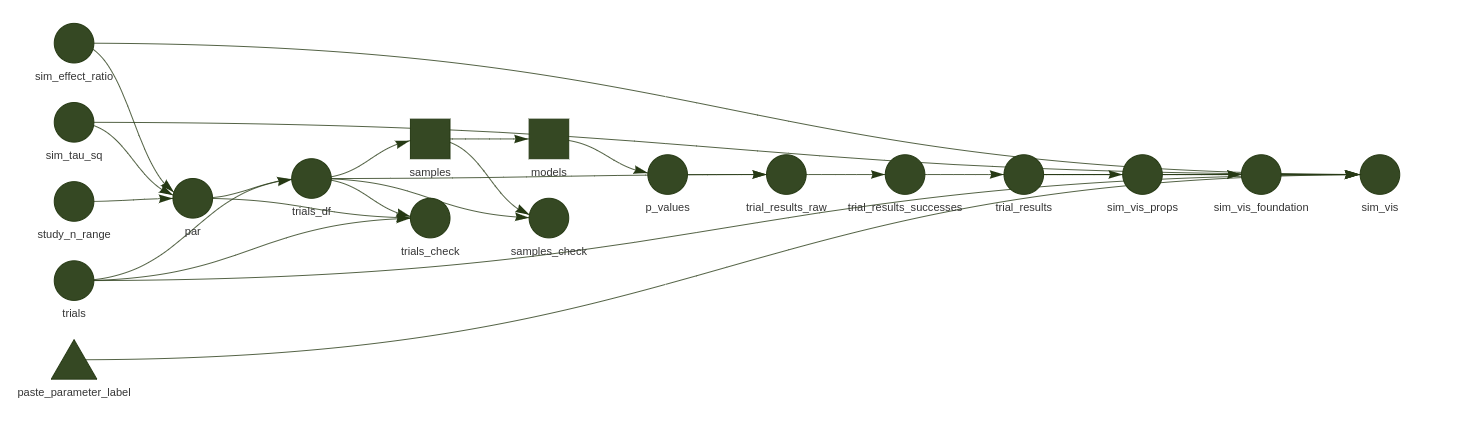
Pipeline to fit 25K meta-analysis models to simulated data, with parameters of interest extracted into a summarised in a ggplot visualisation.
- metafor models
- tidyverse tools
- roxygen documentation
- pkgdown site deployed on github pages
- targets simulation pipeline
What does it do?
